01 About
I work on what a single reported number hides. The thread through my work is measurement: whether a benchmark score survives contamination and memorization checks, whether a learning algorithm's gradients match an independent oracle, and what the internal geometry of a model says that its accuracy cannot. My current manuscript studies the last of these in small open language models. By day I build LLM-backed systems in production; the engineering keeps the research honest about what such measurements can do once deployed.
- born
- 2005, India
- education
- BSc (Hons) Computer Science, K.R. Mangalam University — graduating 2026
- certificates
- IBM — Big Data Engineer (Career Education Program, Oct 2025) · Microsoft Certified: Azure Data Fundamentals (Aug 2025 · code wNNpp-2FMV at verify.certiport.com)
02 Research
D. Shukla. Clustered, Overlapped, or Fractured? The Local-Neighbourhood Geometry of Truth Across Small Multilingual Language Models. Manuscript, 2026. arXiv — soon full results & verification
- 7 models · 4 families0.5B–14B
- 8 languages3 truth concepts
- 2000-sample bootstrap CIspre-registered 14B extension
- controlslabel-permutation · length · random-weight · quantization
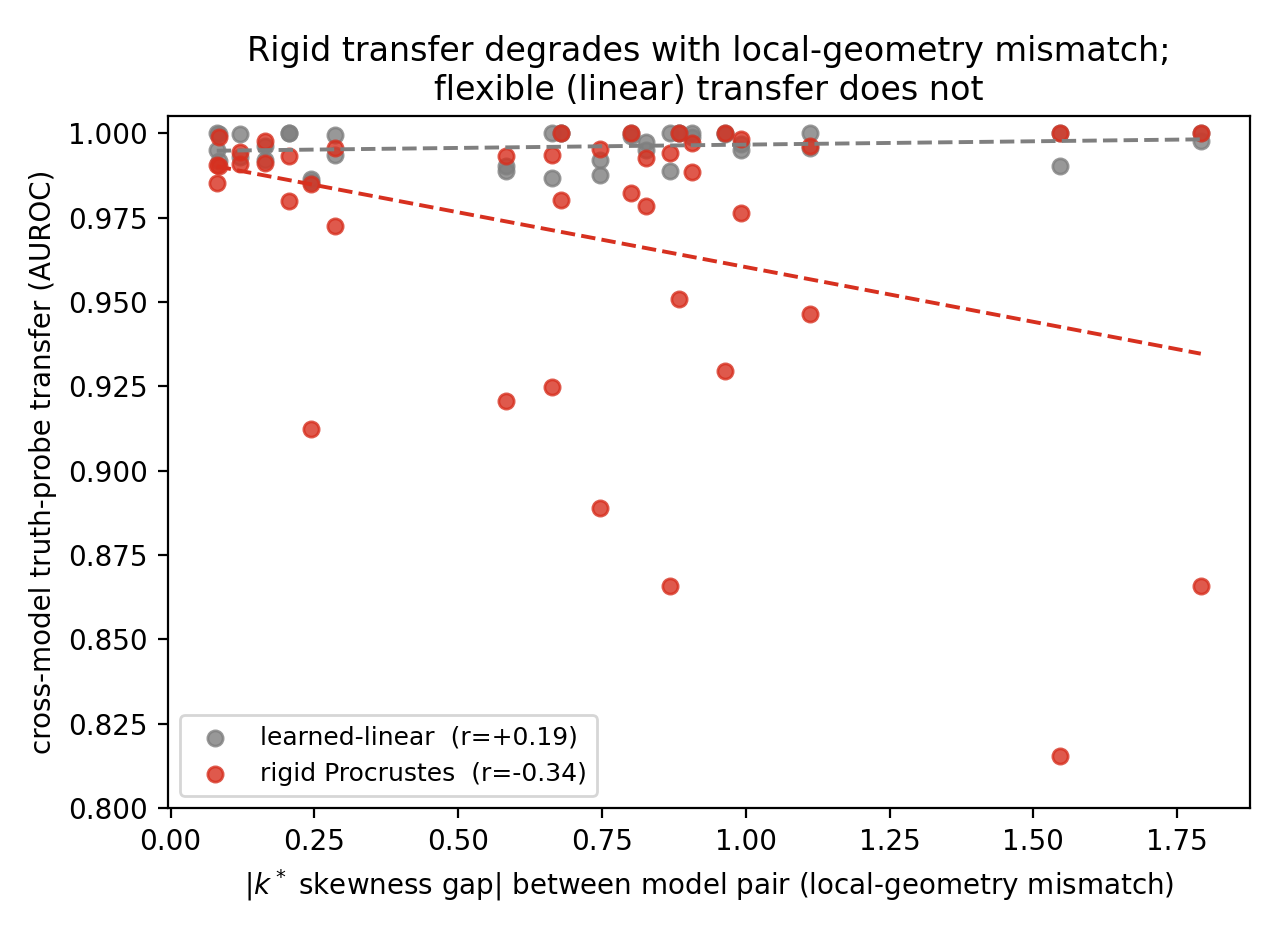
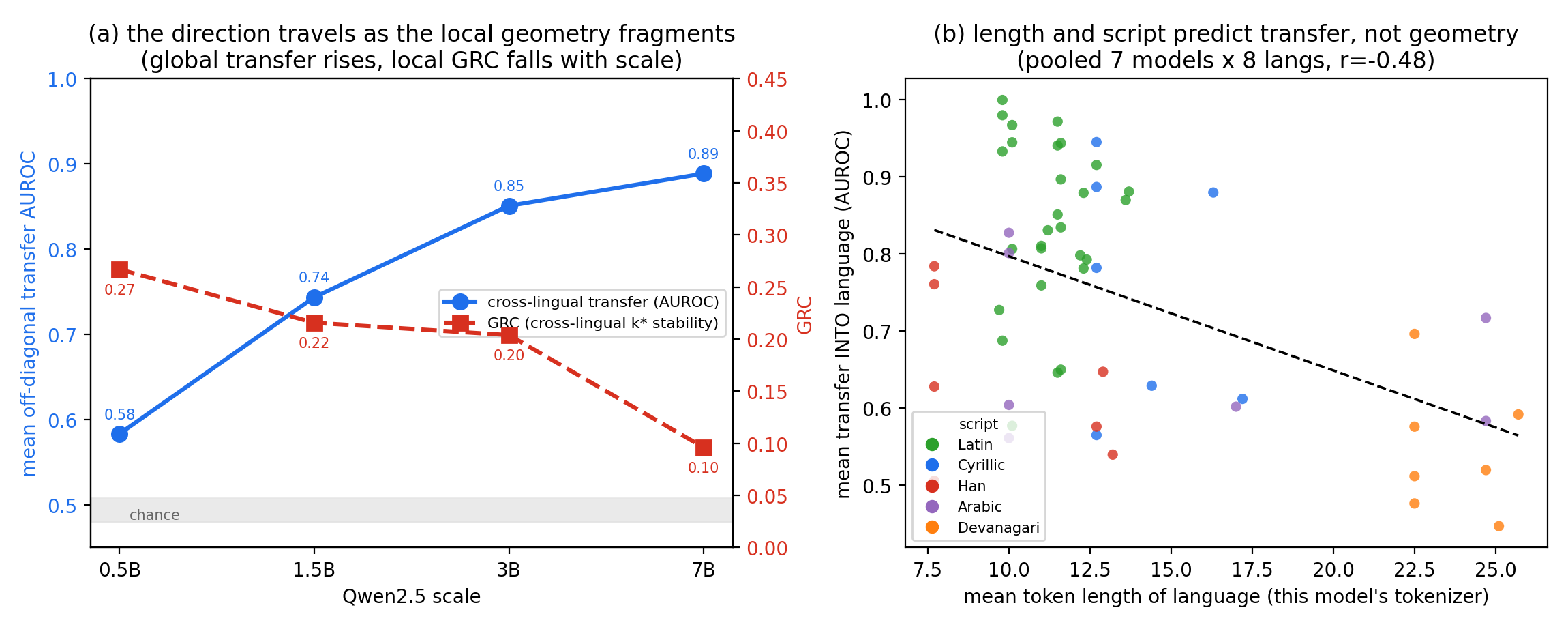
Linear probes read whether a statement is true from a language model's hidden states at ≈0.97–1.00 accuracy. This paper asks what that number hides. It takes the k* distribution (Kotyan, Ueda & Vargas, IEEE TNNLS 2025) — a distortion-free local-neighbourhood statistic — and applies it to the hidden states of autoregressive LLMs for the first time. At matched probe accuracy, the local shape of truth differs by model family (Fractured → Clustered); it changes with scale in a layer- and concept-dependent way; and it is fragile across languages, measured by a new Geometric Reliability Coefficient (GRC). Two controlled negative results show this local geometry does not reliably predict probe transfer: the global truth direction travels across models and languages; the local neighbourhood does not follow.
| measurement | value | note |
|---|---|---|
| linear probe accuracy | 0.97–1.00 | near-perfect decodability, all 7 models — the number the paper looks beneath |
| k* skew across families | −0.51 … +1.29 | full Fractured → Clustered range at matched ≈0.99 probe accuracy |
| GRC across languages | 0.267 → 0.096 | geometric reliability falls with scale while transfer rises |
| cross-model probe transfer | 0.996 vs 0.970 | learned linear vs rigid orthogonal-Procrustes alignment |
instrument — kstar.py (68 lines)
The cleaned, comment-free core instrument, numerically verified against the paper pipeline. Four segments, explained between the code instead of inside it.
1 · Nearest-different-class rank kstar_rank
For each sample, rank all others by distance and count how many same-class neighbours appear before the first different-class one. Supports euclidean / cosine / cityblock / chebyshev; the result depends only on neighbour ranks, not absolute distances.
import numpy as np
def kstar_rank(X, y, metric='euclidean', standardize=False):
X = np.asarray(X, dtype=np.float64)
y = np.asarray(y)
if standardize:
X = (X - X.mean(0, keepdims=True)) / (X.std(0, keepdims=True) + 1e-08)
if metric == 'cosine':
Xn = X / (np.linalg.norm(X, axis=1, keepdims=True) + 1e-12)
D = 1.0 - Xn @ Xn.T
elif metric in ('cityblock', 'l1'):
D = np.abs(X[:, None, :] - X[None, :, :]).sum(-1)
elif metric in ('chebyshev', 'linf'):
D = np.abs(X[:, None, :] - X[None, :, :]).max(-1)
else:
sq = (X * X).sum(1)
D = np.sqrt(np.maximum(sq[:, None] + sq[None, :] - 2 * X @ X.T, 0.0))
np.fill_diagonal(D, np.inf)
order = np.argsort(D, axis=1)
diff = y[order] != y[:, None]
kstar = diff.argmax(axis=1)
has_diff = diff.any(axis=1)
same_counts = (y[:, None] == y[None, :]).sum(1) - 1
return np.where(has_diff, kstar, same_counts).astype(int)2 · Class-size normalisation and typology kstar_normalized, typology_by_class
Divide by the sample's own class cardinality, then label each class by the Fisher–Pearson skewness of its normalised distribution — Fractured (γ > 0.5), Overlapped (|γ| ≤ 0.5), Clustered (γ < −0.5), cut-offs unchanged from the original method.
def _skew_pop(v):
v = np.asarray(v, dtype=np.float64)
sd = v.std()
if sd == 0:
return 0.0
return float(((v - v.mean()) ** 3).mean() / sd ** 3)
def kstar_normalized(raw, y):
y = np.asarray(y)
out = np.empty(len(raw), dtype=np.float64)
for c in np.unique(y):
m = y == c
out[m] = raw[m] / max(int(m.sum()), 1)
return out
def typology_by_class(norm_kstar, y):
y = np.asarray(y)
res = {}
for c in np.unique(y):
v = norm_kstar[y == c]
g = _skew_pop(v)
label = 'Fractured' if g > 0.5 else 'Clustered' if g < -0.5 else 'Overlapped'
res[int(c)] = {'label': label, 'skewness': g, 'mean': float(v.mean()), 'std': float(v.std()), 'n': int(len(v))}
return res3 · Uncertainty gamma_bootstrap_ci
Third moments are noisy at small n, so every reported skewness carries a 2000-resample bootstrap 95% CI.
def gamma_bootstrap_ci(norm_kstar, y, cls, n_boot=2000, seed=0):
v = np.asarray(norm_kstar)[np.asarray(y) == cls]
rng = np.random.default_rng(seed)
n = len(v)
boots = [_skew_pop(v[rng.integers(0, n, n)]) for _ in range(n_boot)]
return (float(np.percentile(boots, 2.5)), float(np.percentile(boots, 97.5)))4 · Cross-lingual stability grc_spearman
GRC = mean pairwise Spearman correlation of per-item normalised k* across languages — rank correlation because k* is itself a rank.
def grc_spearman(norm_kstar_by_lang):
from scipy.stats import spearmanr
langs = list(norm_kstar_by_lang)
vals, pairs = ([], [])
for a in range(len(langs)):
for b in range(a + 1, len(langs)):
r, _ = spearmanr(norm_kstar_by_lang[langs[a]], norm_kstar_by_lang[langs[b]])
r = 0.0 if np.isnan(r) else float(r)
vals.append(r)
pairs.append((langs[a], langs[b], round(r, 3)))
return {'grc': float(np.mean(vals)) if vals else 0.0, 'pairs': pairs}03 Projects
Five self-contained studies sharing one question: when can you trust a reported number? Each entry opens a full page with the results, figures, and code.
-
Memorization probe for LLM benchmarks via meaning-preserving perturbation plus controls.
producedflags a 60%-memorized model (gap 0.260, CI [0.189, 0.331]) and correctly clears a paraphrase-brittle clean one
-
From-scratch MinHash/LSH auditor measuring benchmark inflation from train-eval leakage.
producednaive 0.900 vs corrected 0.870 accuracy at 30% injected leakage; detector recall 1.00, precision ≥ 0.985
-
Leakage-tested link-prediction bake-off: zero-parameter heuristics versus a trained GCN.
producedclustering coefficient predicts the winner (ρ = 0.955); a heuristic matches the GCN on 16/20 graphs
-
NumPy bake-off of TD return estimators under delayed reward.
producedoptimal λ shifts 0.8 → 1.0 as reward delay grows; delay-aware λ beats TD(0) with disjoint CIs (1,600 runs)
-
Reverse-mode autodiff engine from scratch, gradient-verified against PyTorch.
producedgradients match PyTorch to ~3.5e-15 over 500 expressions; trains two-moons to 0.985 with its own Adam
04 Experience
| dates | company | role |
|---|---|---|
| Jun 2026 – present | Gravity | AI Engineer (Junior) |
| Feb 2026 – May 2026 | Gravity | AI Engineer Intern |
| Nov 2025 – Jan 2026 | Vibe AI | Full-Stack Intern |