a Summary
Asks when classical link-prediction heuristics (common neighbors, Adamic-Adar, resource allocation, Katz, personalized PageRank) match a trained GNN, and whether graph topology predicts the winner. A 2-layer GCN (8,512 parameters, implemented from raw sparse ops, no PyG) is compared against five zero-parameter heuristics on 20 generated graphs (5 generator families × 2 configurations × 2 seeds).
Everything is scored by one shared Hits@20 evaluator on identical negative samples, with message passing restricted to training edges and an automated audit that hashes every run's edge set. Four fairness invariants are each enforced by a test; the README explicitly declines to claim the non-significant gap-size correlation.
b Results
| measurement | value | note |
|---|---|---|
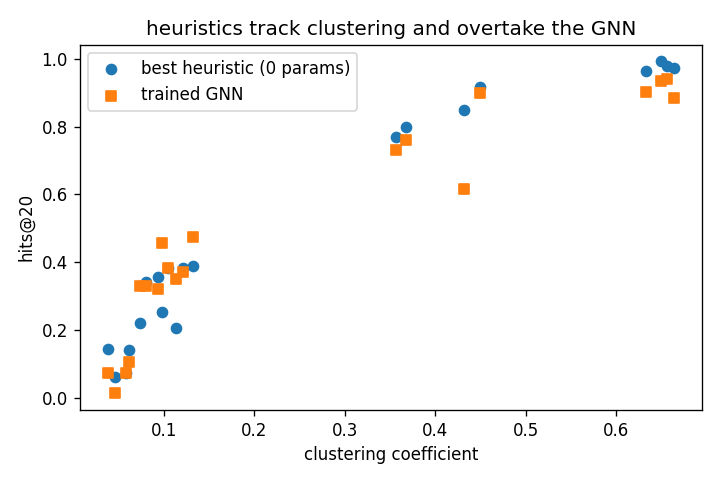
| clustering predicts heuristic accuracy | Spearman ρ = 0.955, p = 6.2e-11 | n = 20 graphs |
| heuristic matches or beats GCN | 16/20 graphs | 0 parameters vs 8,512 |
| GCN wins (Hits@20) | 0.380 vs 0.320; 0.374 vs 0.299 | only low-clustering families: barabasi_albert, stochastic_block |
| leakage audit | 0 leaked edges, 20/20 clean | hashed edge sets, every run |
| honest non-result | ρ = 0.354, p = 0.125 | gap size vs clustering — reported as not significant |
caveat200-node synthetic graphs with a plain 2-layer GCN; no real benchmark (e.g. ogbl-collab) yet.
c Code
Katz via truncated power series — beta fixed a priori from the spectral radius — gvh/heuristics.py. Full source and tests are on GitHub; the walkthrough notebook reproduces the results table above in Colab.
def katz_matrix(adj, beta=None, beta_ratio=0.5, max_power=6):
A = adj.tocsr().astype(np.float64)
if beta is None:
beta = beta_ratio / largest_eigenvalue(A)
power = A
katz = beta * A
coef = beta
for _ in range(2, max_power + 1):
power = power @ A
coef = coef * beta
katz = katz + coef * power
return katz.tocsr(), beta- stack
- Python, PyTorch (hand-rolled GCN, no PyG), NetworkX, SciPy sparse, pandas
- tests
- 21 pytest tests - GitHub Actions CI (ruff + pytest)
- notebook
- notebooks/01_walkthrough.ipynb on Colab