a Summary
A from-scratch reverse-mode automatic differentiation engine built to verify, not just reproduce, how backprop works: a scalar Value engine plus a numpy Tensor engine with broadcasting-aware gradients, an MLP/losses layer, and SGD/Momentum/Adam written from first principles.
Every operator's gradient is checked two independent ways — central finite differences and PyTorch float64 autograd — on the argument that the two oracles fail differently, so agreement with both is strong evidence of correctness.
b Results
| measurement | value | note |
|---|---|---|
| parity vs PyTorch | ~3.5e-15 | worst max gradient difference over 500 random expressions (machine epsilon) |
| per-op asserts | < 1e-6 | finite-difference agreement ~1e-7 |
| two-moons MLP (2-16-16-1) | 0.985 accuracy | trained with its own Adam; CI-enforced test asserts > 0.95 |
| edge cases | diamond graphs, variable reuse | gradient-accumulation tests |
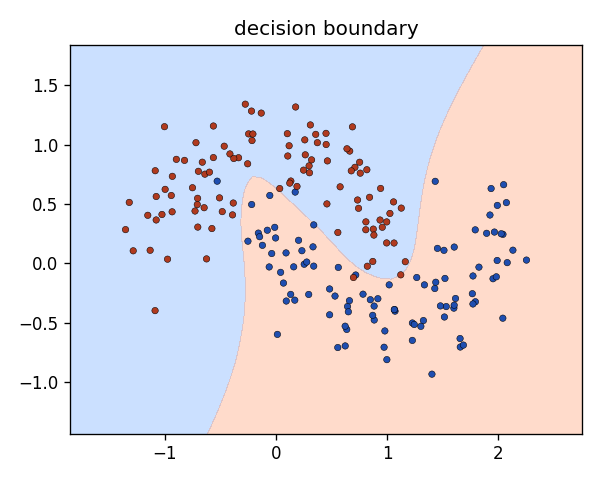
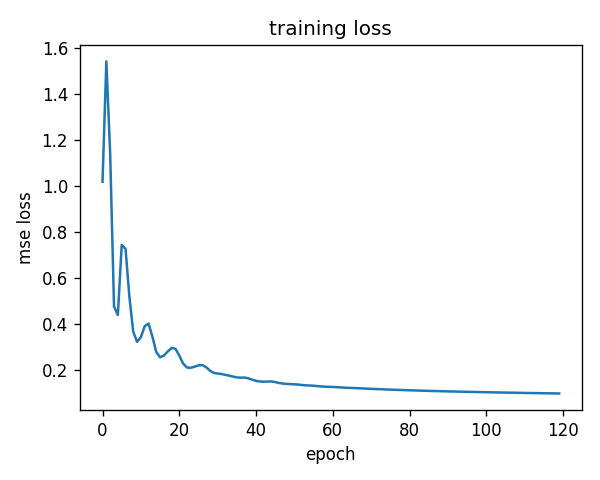
caveatPedagogical scale — the tensor engine covers add/mul/matmul/relu/sum; no GPU; only toy-task training.
c Code
broadcast-aware product rule and matmul gradients via backward closures — tinygrad_scratch/tensor.py. Full source and tests are on GitHub; the walkthrough notebook reproduces the results table above in Colab.
def __mul__(self, other):
other = other if isinstance(other, Tensor) else Tensor(other)
out = Tensor(self.data * other.data, (self, other), "*")
def _backward():
self.grad = self.grad + _unbroadcast(other.data * out.grad, self.data.shape)
other.grad = other.grad + _unbroadcast(self.data * out.grad, other.data.shape)
out._backward = _backward
return out
def matmul(self, other):
out = Tensor(self.data @ other.data, (self, other), "@")
def _backward():
self.grad = self.grad + out.grad @ other.data.T
other.grad = other.grad + self.data.T @ out.grad
out._backward = _backward
return out- stack
- Python, numpy (sole runtime dependency); dev: PyTorch (parity oracle), pytest, ruff
- tests
- 28 pytest tests - GitHub Actions CI (ruff + pytest)
- notebook
- notebooks/01_walkthrough.ipynb on Colab