a Summary
Asks whether a model's headline benchmark accuracy is partly memorization: if items are rewritten meaning-preservingly, does accuracy drop more on the public benchmark than on a fresh, difficulty-matched control set? Three perturbation operators are implemented for GSM8K-style word problems — an identity null, numeric resampling that recomputes the gold answer by re-evaluating the problem's own calculator chain, and entity renaming.
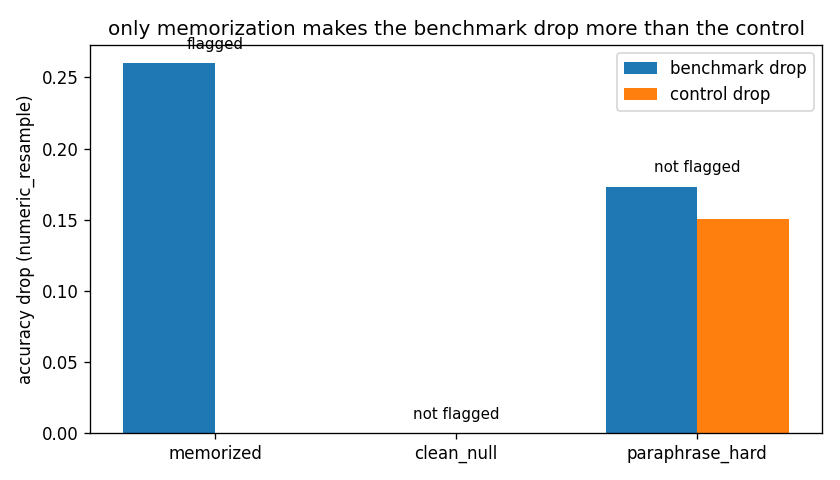
The decision rule flags memorization only when the bootstrap 95% CI of the gap (benchmark drop − control drop) excludes zero. The harness is validated end-to-end on three simulated models with known ground truth (memorized, clean, paraphrase-brittle) over 300 GSM8K items; all three are classified correctly. A real model plugs in via a one-method is_correct(item) interface.
b Results
| measurement | value | note |
|---|---|---|
| gap — memorized model | 0.260, CI [0.189, 0.331] | numeric_resample; correctly flagged |
| gap — paraphrase-brittle model | 0.023, CI [−0.064, 0.115] | correctly NOT flagged — the case a control-free probe would misclassify |
| identity-null drop | 0.000, McNemar p = 1.0 | no harness artifact (n = 150) |
| perturbation coverage | 127/150 items | numeric_resample; McNemar p = 2.5e-08 on the memorized model |
caveatNo real LLM is evaluated — results validate the harness on simulated models with known memorization; the real-model runner is an interface stub.
c Code
the gap estimator — paired bootstrap over both sets — perturbbench/experiment.py. Full source and tests are on GitHub; the walkthrough notebook reproduces the results table above in Colab.
def drop_gap(model, benchmark_items, control_items, perturb_fn, seed=0, n_boot=2000):
bo, bp = _eval_pairs(model, benchmark_items, perturb_fn, seed)
co, cp = _eval_pairs(model, control_items, perturb_fn, seed)
bench_drop = float(bo.mean() - bp.mean())
ctrl_drop = float(co.mean() - cp.mean())
rng = np.random.default_rng(seed + 1)
gaps = np.empty(n_boot)
for i in range(n_boot):
bi = rng.integers(0, len(bo), size=len(bo))
ci = rng.integers(0, len(co), size=len(co))
gaps[i] = (bo[bi].mean() - bp[bi].mean()) - (co[ci].mean() - cp[ci].mean())
return {"bench_drop": bench_drop, "ctrl_drop": ctrl_drop,
"gap": bench_drop - ctrl_drop,
"gap_lo": float(np.percentile(gaps, 2.5)),
"gap_hi": float(np.percentile(gaps, 97.5))}- stack
- Python, numpy, pandas, scipy, matplotlib
- tests
- 21 pytest tests - GitHub Actions CI (ruff + pytest)
- notebook
- notebooks/01_walkthrough.ipynb on Colab