a Summary
Asks whether the best return estimator for value prediction changes measurably as reward delivery is delayed. TD(0), n-step TD, TD(λ) with eligibility traces, and GAE are implemented from scratch in NumPy, with the unifying identities (λ=0 ≡ TD(0), λ=1 ≡ Monte Carlo, λ-return ≡ n-step mixture, GAE ≡ λ-return − V) encoded as pytest tests.
Correctness is validated by reproducing the Sutton & Barto 19-state random-walk figure and checking the gridworld learner against closed-form values from a linear solve. The main experiment sweeps 5 λ × 4 delays × 4 step sizes × 20 seeds = 1,600 runs with α tuned per cell.
b Results
| measurement | value | note |
|---|---|---|
| optimal λ vs delay | 0.8 → 1.0 | shifts toward Monte Carlo as delay grows (delay 0 → 8) |
| delay-aware λ vs TD(0), RMS | 0.118 vs 0.196 · 0.152 vs 0.234 · 0.132 vs 0.231 | delays 2/4/8 — 95% bootstrap CIs disjoint at all three |
| TD(0) under delay | 0.116 → 0.231 | error roughly doubles from delay 0 to 8 |
| validation | n = 4 min RMS 0.0854 | reproduces the classic random-walk shape (intermediate n wins) |
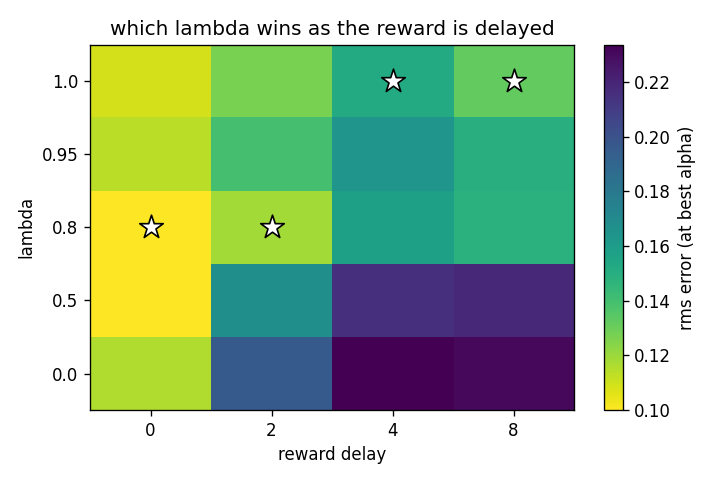
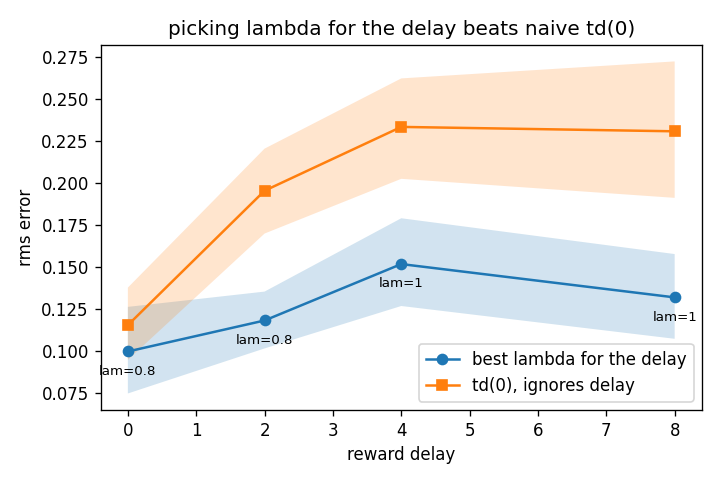
caveatPrediction-only on tiny tabular environments; a delay-blind lambda = 1 baseline already captures most of the benefit.
c Code
the single backward recursion everything reduces to — cab/returns.py. Full source and tests are on GitHub; the walkthrough notebook reproduces the results table above in Colab.
def lambda_return(rewards, values, gamma, lam):
rewards = np.asarray(rewards, dtype=float)
values = np.asarray(values, dtype=float)
T = len(rewards)
out = np.zeros(T)
g = values[T]
for t in reversed(range(T)):
g = rewards[t] + gamma * ((1 - lam) * values[t + 1] + lam * g)
out[t] = g
return out- stack
- Python, NumPy, pandas, matplotlib, joblib, SciPy
- tests
- 15 pytest tests + result-level regression tests - GitHub Actions CI
- notebook
- notebooks/01_walkthrough.ipynb on Colab