a Summary
Quantifies how much of a text benchmark's accuracy is an artifact of train/eval contamination rather than generalization. MinHash signatures and banded LSH are implemented from scratch (plus a TF-IDF cosine matcher for cases MinHash misses), and the matcher is validated on 200 seeded duplicate pairs across five controlled edit types before any claim is made.
Known leakage is then injected into an AG News classification task (6,000 documents; 4 contamination levels × 3 seeds) and naive versus leakage-corrected accuracy is reported. A third experiment (36 retrains) shows dedup-first pruning dominates random pruning. Ships a data-audit CLI with dedup and leakage subcommands.
b Results
| measurement | value | note |
|---|---|---|
| naive vs corrected accuracy | 0.900 vs 0.870 | at 30% injected contamination — a 3-point illusory gain; gap exactly 0.000 at zero leakage |
| detector on injected leakage | recall 1.00, precision 0.985–0.997 | the accuracy gap exceeds the false-positive rate |
| matcher validation | precision 1.0 at all 9 thresholds | honest failure reported: both matchers 0.0 recall on heavy paraphrase |
| pruning at 30% data removal | −0.6 vs −1.0 points | dedup-first vs random ordering (means over 3 seeds) |
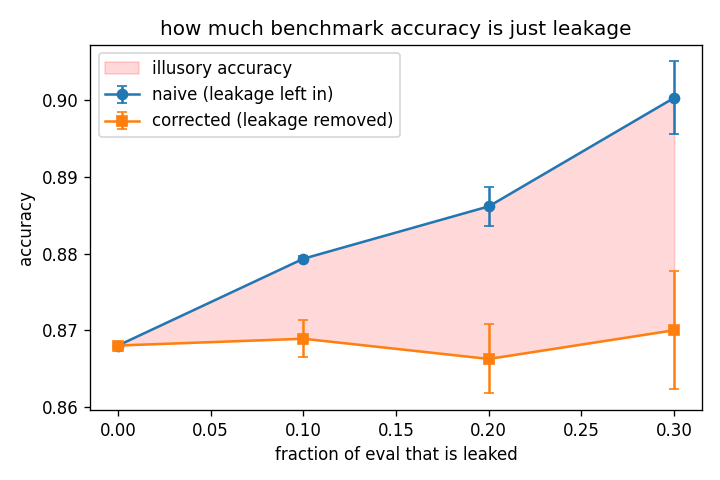
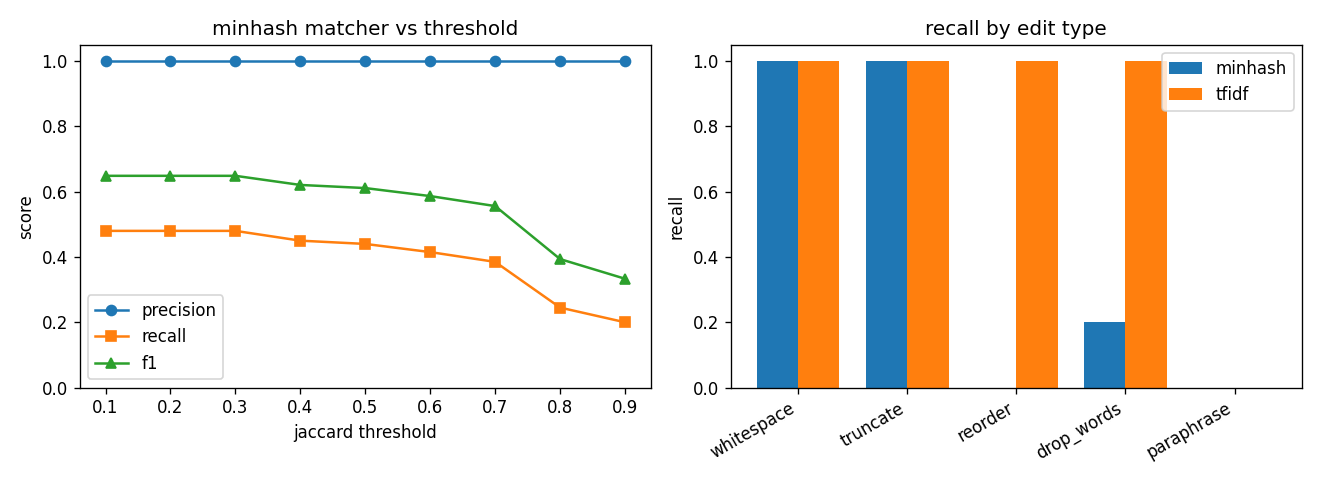
caveatInjected near-exact lexical duplicates on one dataset with a linear classifier; paraphrased contamination would need an embedding-based matcher.
c Code
the MinHash core — vectorized universal hashing over a Mersenne prime — data_audit/minhash.py. Full source and tests are on GitHub; the walkthrough notebook reproduces the results table above in Colab.
class MinHasher:
def __init__(self, num_perm=128, seed=0):
rng = np.random.default_rng(seed)
self.num_perm = num_perm
self.a = rng.integers(1, _PRIME, size=num_perm, dtype=np.uint64)
self.b = rng.integers(0, _PRIME, size=num_perm, dtype=np.uint64)
def signature(self, shingles):
if not shingles:
return np.full(self.num_perm, _PRIME, dtype=np.uint64)
h = np.array([_base_hash(s) for s in shingles], dtype=np.uint64)
hashed = (self.a[:, None] * h[None, :] + self.b[:, None]) % _PRIME
return hashed.min(axis=1)
def jaccard_estimate(sig1, sig2):
return float(np.mean(sig1 == sig2))- stack
- Python, NumPy, pandas, scikit-learn (classifier/TF-IDF only), CLI entry point
- tests
- 17 pytest tests - GitHub Actions CI (ruff + pytest)
- notebook
- notebooks/01_walkthrough.ipynb on Colab